作为一名爱折腾的玩家,我最近沉迷于调教AI模型。从PVE、飞牛NAS到OpenWrt,我习惯为系统寻找最佳扩展方案。而在AI领域,RAG和向量数据库正是这样一个“史诗级增强包”,它能从根本上解决大模型的知识短板和幻觉问题,让AI真正变得有用、可靠。
一、 问题的根源:AI为什么会“胡说八道”?
我们常常陷入两种极端情绪:一边惊叹于AI展现的“人类智能”,一边又为它一本正经地编造答案而抓狂。这种现象,业界称之为 “AI幻觉”(AI Hallucination)。
其根源主要在于两点:
概率生成机制:大模型本质上是通过统计概率预测下一个词,而不是查询事实数据库。这就像让一个知识渊博但记忆模糊的学者即兴演讲,难免会“自由发挥”。
知识范围局限:模型的认知完全禁锢在其训练数据中。它不知道你公司的内部文档,也不了解你今天午餐吃了什么。对于这些“知识盲区”,它只能靠“想象力”填补。
目前,基于Transformer架构的模型还无法根除幻觉。但聪明的工程师们想出了一个巧妙的“外挂”方案——RAG。
二、 解决方案:RAG(检索增强生成)是什么?
RAG 的全称是 Retrieval-Augmented Generation(检索增强生成)。这个名字听起来复杂,但原理很直观:给大模型接上一个外部“知识库”(向量数据库),让它回答问题前先“查资料”。
我们可以用一个智能客服的场景来理解它:
场景:你是一家汽车公司的CEO,想让AI客服回答用户关于“中控屏黑屏”的故障咨询。
传统AI:可能基于训练数据泛泛而谈,甚至给出错误的车系维修方案。
RAG增强的AI:
检索:将用户问题转化为向量,在你的向量数据库(里面存储了所有产品手册、故障代码等内部资料)中,快速找到最相关的官方解决方案文档片段。
增强:把这些查到的准确资料(称为
context 上下文)和用户问题一起,组装成一个新的提示词,交给大模型。生成:大模型基于确凿的
context进行推理和总结,生成一个准确、可靠的回答,例如:“您好,根据您的车型和故障现象,请尝试长按电源键15秒强制重启。若无效,请参考手册第X章,检查XX号保险丝。”
RAG带来的三大好处:
大幅减少幻觉:回答基于提供的事实,而非凭空想象。
注入新知识和私有信息:可以随时用最新的公司文档、技术资料更新知识库,让模型“与时俱进”。
成本低廉,易于更新:相比重新训练(Fine-tuning)模型动辄耗费巨资,RAG只需要更新向量数据库,是AI落地的关键技术。
三、 核心引擎:向量数据库是如何工作的?
RAG的“外挂知识库”并非一个普通的文档仓库,而是一个专门的向量数据库。它是整个系统的“记忆心脏”。其工作流程可以分为“存”和“取”两部分。
第一步:知识入库 - 从文档到向量
文档分块:将PDF、Word等知识库文档切割成有意义的文本片段(Text Chunking)。分块质量直接决定检索效果。
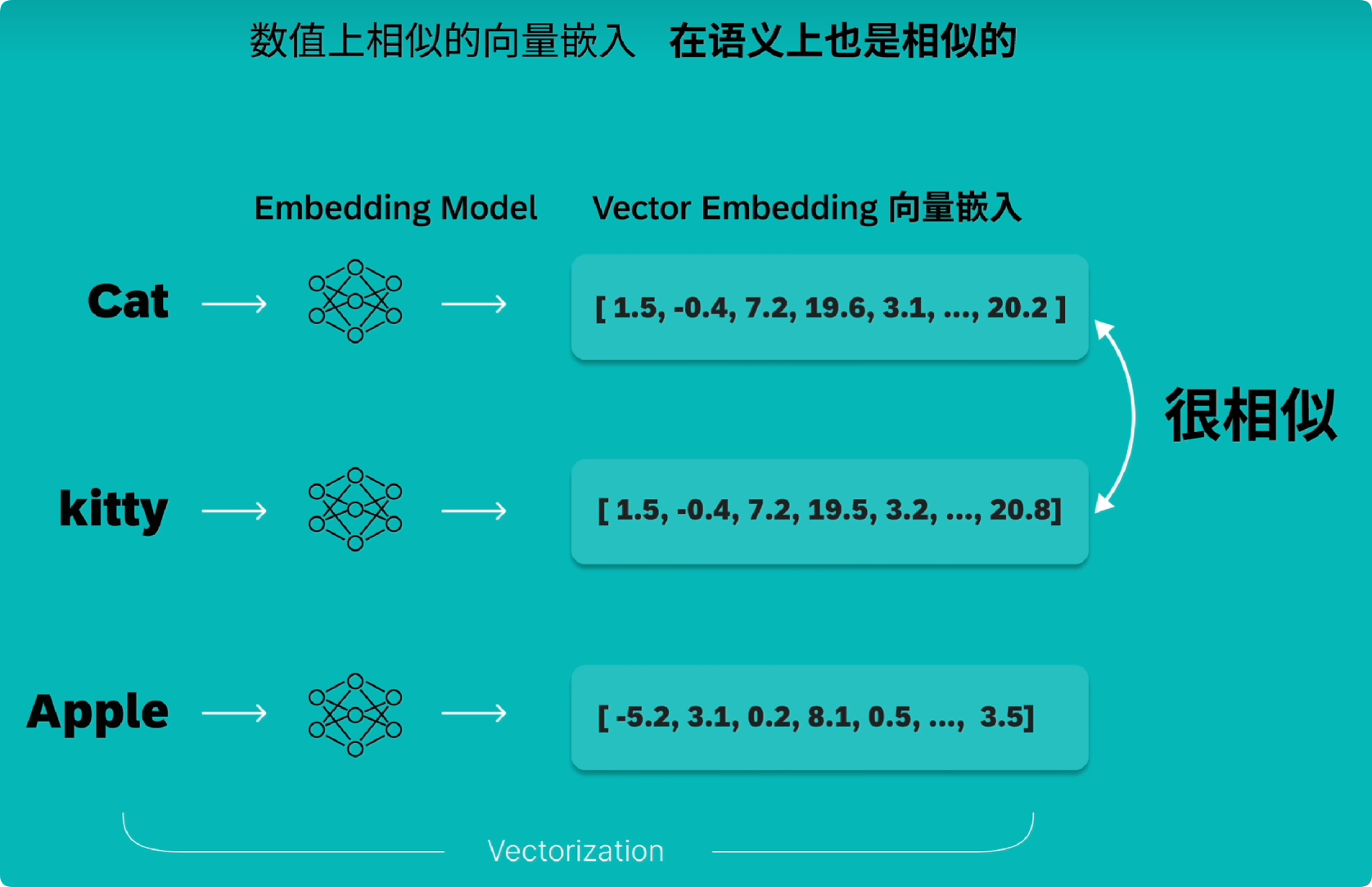
向量化:通过嵌入模型(Embedding Model),将文本块转换为向量嵌入(Vector Embedding)。你可以把它理解为一串能捕捉语义的数字指纹(比如几百到几千个数字组成的一个数组)。
关键点:语义相似的文本,其向量在数字空间中也“距离”更近。例如,“猫”和“小猫”的向量非常接近,而“猫”和“苹果”的向量则相差甚远。OpenAI提供了可视化工具,能直观展示不同概念在向量空间的聚集情况。
第二步:智能检索 - 从问题到答案
查询转换:当用户提问时,系统用同样的嵌入模型将问题也转化为一个查询向量。
相似性搜索:在向量数据库中,快速找到与“查询向量”最相似的N个“文档向量”。这个寻找“最近邻”的过程,就是检索(Retrieval),也是RAG中“R”的由来。
重排序:初步检索出的N个结果,可能会经过一个重排序(Re-ranking) 模型进行精细调整,筛选出与问题最相关的前Top K个片段,作为最优质的
context。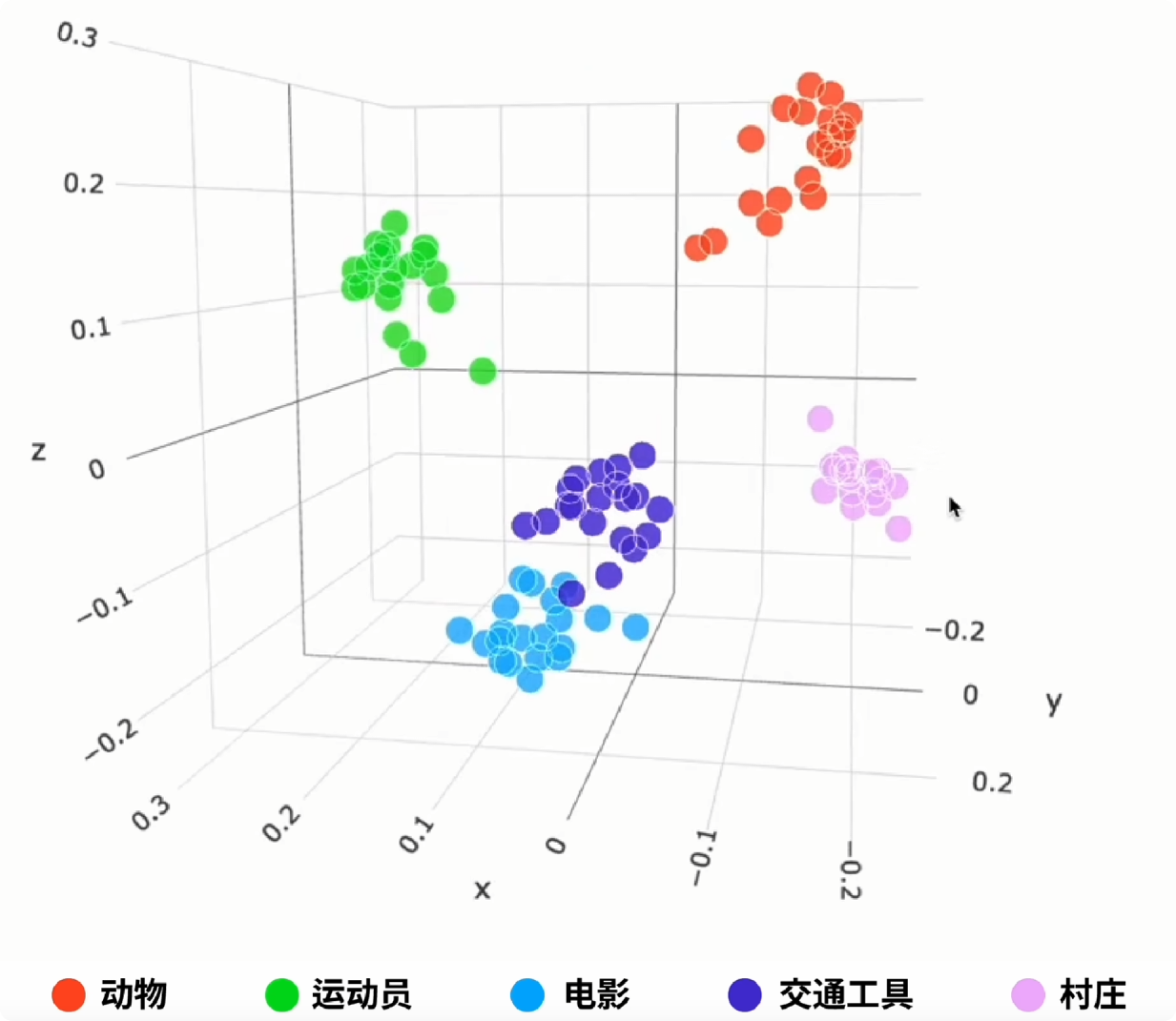
向量搜索的关键技术:如何衡量“相似”?
计算机通过数学公式计算向量间的“距离”或“夹角”来判断相似度。最常用的指标是余弦相似度:
值范围在-1到1之间。1表示完全相同,0表示无关,-1表示完全相反。
它专注比较向量的方向夹角,不受文本长度影响,非常适合处理自然语言。计算“国王”和“皇后”的向量,可能会得到0.03的相似分,而“狗”和“狼”的分数则会高得多。

向量数据库 vs. 传统数据库
传统数据库:存储结构化数据(表格、数字、日期),通过精确的SQL语句查询。
向量数据库:存储非结构化数据(文本、图片、音频)的向量表示,专为相似性搜索优化。它能理解语义,对同义词、模糊表达有很好的包容性,是实现高级AI应用的基础设施。
市面上有 Pinecone、Milvus 等专业的向量数据库解决方案。
四、 总结与展望
总结一下,RAG的完整流程就是:文档 -> 分块 -> 向量化 -> 存入向量数据库 -> 用户提问 -> 问题向量化 -> 相似性搜索 -> 获取上下文 -> 组合提示词 -> 大模型生成 -> 返回答案。
向量数据库背后的高效检索,依赖于ANN(近似最近邻) 等算法,这就像在浩瀚星图中快速定位最近的行星。
希望这篇梳理能帮你打通RAG和向量数据库的“任督二脉”。作为技术爱好者,持续探索这些能将理论知识转化为实用工具的方案,正是最大的乐趣所在。如果你有更多想法,欢迎在评论区一起交流!